One hierarchy, many algorithms
Geometrical modeling projects often contain some form of central hierarchy of objects. A geometric kernel, for example, has a hierarchy of geometric entities. Another example is a geometric solver which has a hierarchy of objects and constraints. Simplified inheritance diagrams for these hierarchies are shown in the figures below.
Many routines/algorithms of other modules need to process all the entities in a hierarchy in a similar fashion, although with different implementation details. So, polymorphism naturally is used with these kinds of hierarchies.
Assuming we are talking about C++ (and this is usually the programming language of choice for algorithmic libraries in CAD), using virtual functions is the first consideration for implementing polymorphic behaviour.
However, a variety of routines applied to the entire hierarchy, or even part of it, is usually quite big. When speaking of geometric solvers, this would include translate/update (to systems of equations and back), validation (for constraints), auxiliary object calculations, technical stuff like serialization/deserialization, and UI representation.
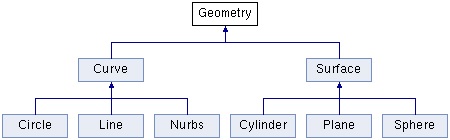
A simplified hierarchy of entities in Geometric kernel
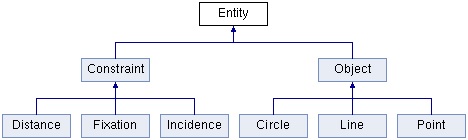
A simplified hierarchy of entities in Geometric solver
If we were to place all of these functiontions as virtual functions in the base, each of the derivative classes would clutter the hierarchy, create huge classes and break the “single responsibility” principle.
class Entity { public: virtual bool Validate() = 0; virtual void Update(SystemContext*) = 0; virtual void Translate(SystemContext*) = 0; virtual void Serialize(Stream*) = 0; virtual void Deserialize(Stream*) = 0; virtual void Draw(DrawContext*) = 0; // ... };
Besides the problem of loading the base object with too many responsibilities (and thus making an ugly, hard to read interface), there are other problems with such an approach.
One of the problems is that adding a new algorithm to the system requires modifying all of the hierarchy, by adding a new virtual method to every class of the hierarchy. This not only affects compilation time, but also prevents any algorithms from being put into separate libraries/executables. For example, the Draw() method would be better implemented in the GUI application, instead of the core computational library.
Another problem arises when we need the algorithm to handle only the part of the hierarchy (e.g., only the constraints, but not the objects). In this case we either have to place the virtual function in the very base class (but then have an empty implementation in all the irrelevant objects) or else put it into the first suitable successor in the hierarchy. The former option additionally worsens the interface of the base class with irrelevant functions, while the latter requires to downcast objects to the required class in hierarchy, which breaks the whole idea of using the virtual functions.
The problems I mention here were really bothering us in our software projects, so applying a Visitor pattern was very beneficial in refactoring, which allowed us to make good progress in code organization.
From “switch” statement to virtual functions
Polymorphism provided by virtual functions is a core basis of object-oriented design, which allows client code to work uniformly with all objects in the hierarchy, using the interface of the base class. It is considered a major step forward, as compared to switch statements with downcasting.
Let’s look at these approaches with a simple example. (For simplicity, only two classes of hierarchy are shown and all names are simplified, keeping in mind that such names are highly not recommended for industrial code!) We assume a very common scenario, in which the client code works with an array of objects in the hierarchy, holding them as pointers to the base class. The switch statement implementation looks like this:
void SerializeEntity(Stream* s, Entity* e) { switch (e->GetType()) { case tPoint: { Point* p = static_cast<Point*>(e); // put data of p into s break; } case tLine: { Line* l = static_cast<Line*>(e); // put data of l into s break; } // ... default: break; } } /// CLIENT CODE void Serialize(Stream* s, const vector<Entity*>& ents) { for (auto ent : ents) { SerializeEntity(s, ent); } }
The virtual functions implementation distributes logic between classes of hierarchy, but no casting is required:
class Point : public Object { public: virtual void Serialize(Stream* s) { /* put data of p into s */ } }; class Line : public Object { public: virtual void Serialize(Stream* s) { /* put data of l into s */ } }; /// CLIENT CODE void Serialize(Stream* s, const vector<Entity*>& ents) { for (auto ent : ents) { ent->Serialize(s); } }
It is worth noting that the switch statement version still relies on one virtual function, GetType(). Then we need to downcast to derived classes to extract specific information, such as the origin/direction of lines. A similar approach without using virtual functions is to employ a series of dynamic_casts with checks for non-zero results.
Everyone knows that using casts usually signals bad design, so there is no doubt that the first implementation is not well written. Casts (static) can cause undefined behaviour or (dynamic) require additional checks and slow down performance. Moreover, introducing changes to the hierarchy (such as adding a new type of object) requires programmers to look through all of the code in a search of “switch” and “if-else” blocks, and then extending them accordingly. This is what polymorphism was intended to resolve.

However, as discussed above, the virtual functions approach also has serious drawbacks. It fills the entity’s public interface with tons of functions completely unrelated to one another. Moreover, it spreads the algorithm’s logic (e.g., serialization logic, modelling logic, and so on) between different classes of hierarchy, and so between different files. This makes it harder to refactor, to extract common parts of the functionality — thus provoking code duplication.
So, we would like to have some kind of valid object-oriented solution that still keeps the code of the same algorithm for different types in the hierarchy close to one another (like in the “switch-case” approach), but avoiding the ugly casts. Visitor pattern provides us with such an opportunity.
… and “back” to Visitor

Let’s see how the visitor-based implementation looks like. (Note: in the real code, either Accept() function of hierarchy classes or Visitor class methods have to be implemented in a .cpp file to allow forward declaration and avoid cyclic dependencies; the code shown here is simplified for compactness.)
class Visitor; class Entity { public: virtual void Accept(Visitor& v) {v.VisitEntity(this); } }; class Point : public Object { public: virtual void Accept(Visitor& v) { v.VisitPoint(this); } }; class Line : public Object { public: virtual void Accept(Visitor& v) { v.VisitLine(this); } }; class Visitor { public: virtual void VisitEntity(Entity* e) {} virtual void VisitObject(Object* o) { VisitEntity(o); } virtual void VisitPoint(Point* p) { VisitObject(p); } virtual void VisitLine(Line* l) { VisitObject(l); } }; class Serializer : public Visitor { public: Serializer(Stream* s, Entity* e) :_s(s) { e->Accept(*this); } virtual void VisitPoint(Point* p) { /* put data of p into _s */ } virtual void VisitLine(Line* l) { /* put data of p into _s */ } private: Stream* _s; }; /// CLIENT CODE void Serialize(Stream* s, const vector<Entity*>& ents) { for (auto ent : ents) { Serializer(s, ent); } }
Instead of a separate virtual function for each algorithm in the Entity class, we again have a just one virtual function, Accept(), responsible to dispatch any algorithm class, derived from Visitor, into the proper subclass of the hierarchy.
All the disadvantages of virtual functions in the base class are now eliminated:
- Entity interface is now clean, containing only one “technical” function for all of the algorithms
- Algorithm class now again holds together all the code related to the algorithm, so code duplication can be easily eliminated
- Visitor subclasses do not necessarily belong to the same module, so, for example, a “Drawer” visitor can now be implemented in a GUI executable directly, interacting with the corresponding canvas/painting classes
One of the drawbacks of the “switch statement approach” is back again: when extending the hierarchy with the new subtype, we need to check all the visitors to see which of them has to be extended with corresponding Visit… functions. However, searching for subclasses of Visitor is a much more regular task compared to looking for switch statements or casts to subclasses of the hierarchy — especially when we remember that some developers prefer to use C-style casts to using C++ casts. In fact, modern IDEs assist in this task, providing the ability to find all subclasses of a specific class.
In any case, in the projects we work with, the main hierarchy is usually formed at the start of the project, while various processing algorithms are added during the whole project lifecycle. Thus, we usually rather add new visitors than extend them with new processing functions. This really is the scenario for which Visitor is best suited.
Base Visitor class: abstract, or with empty implementations?
When implementing a Visitor pattern it is popular to make the base Visitor class abstract, leaving VisitSomething() functions purely virtual. This might seem a smart choice, because it will guarantee that all Visitors will be reviewed when a new class is added to the hierarchy. At the very least, an empty implementation will have to be added to each of the derived Visitors to compile.
However, we strongly prefer the implementation listed above: all functions of the base Visitor class have implementations, calling the Visit of the direct predecessor in the hierarchy. (The topmost class’ function is empty.) This leads to two benefits, as described next.
Implementation for the needed classes only
Some algorithms make sense for only part of the hierarchy. For example, we might want to draw only objects and not constraints. In this case we just implement the corresponding functions for the visitor, and so do not have to tediously list all of the other functions corresponding to the whole hierarchy.
class Drawer: public Visitor { public: Drawer(Canvas* c) :_c(c) { } // Draw what you want only virtual void VisitPoint(Point* p) { /* ... */ } virtual void VisitLine(Line* l) { /* ... */ } virtual void VisitCircle(Circle* c) { /* ... */ } private: Canvas* _c; };
Compare this to the virtual base Visitor approach: you need a Visitor for, for example, just lines and points, but you have to list all, say, 30 classes of the hierarchy with empty implementations. There is a great temptation to write a couple of dynamic_casts instead. On the contrary, if you write a class with just two functions, you most likely will prefer that to the casts.
Common implementation for part of the hierarchy
If the processing of a certain algorithm is the same for all subclasses of some intermediate class of the hierarchy (for example, all constraints must be processed equally), then it is sufficient to implement a corresponding function of the visitor — VisitConstraint in our example. The following code demonstrates a trivial example of a common processing filter:
class ConstraintsFilter : public Visitor { public: ConstraintsFilter(const vector<Entity*>& iEnts) { for (auto ent : iEnts) { ent->Accept(*this); } } vector<Constraint*> operator()() const { return _constraints; } void VisitConstraint(Constraint* c) { _constraints.push_back(c); } private: vector<Constraint*> _constraints; }; /// CLIENT CODE vector<Constraint*> cst = ConstraintsFilter(ents)();
The sequence of calls is very elegant:
- When particular constraint object (e.g., object of Distance class) accepts the derived visitor (ConstraintsFilter), VisitDistance() function is called
- Since this function is not implemented in ConstraintsFilter, its implementations from the base class (Visitor) is called
- Due to the implementation we showed above, Visitor::VisitDistance looks like this:
virtual void VisitDistance(Distance* d) { VisitConstraint(d); }
- In turn, VisitConstraint is a virtual function, which does have overload in the ConstraintFilter; thus this overloaded function is called and so the entity is added to _constraints array
- Non-constraints fall into Visitor::VisitEntity() with empty implementations
Conclusion
Using the Visitor pattern in projects that have some kind of main hierarchy is a major architecture improvement that we like a lot and currently apply to many of our projects. It allows us to separate algorithms from objects, providing algorithm access to the subclass API to which the object really belongs. A typical project might have several dozen visitors, sometimes implementing just one-to-two functions for certain parts of the hierarchy.
Read more:
Fast Debug in Visual C++
How to Hack C++ with Templates and Friends
On C++ code bloat
Which Missing C++ Features Are Needed Most?